


")

2772.svg?ext=.svg "CPAWSB Introduces Equity, Diversity, and Inclusion (EDI) Resources for Learners and Contractors")


Additional Resources

Typingstudy.com
Test your current typing speed and accuracy using an English keyboard. You can also complete key drills, lessons, and complete typing tests to gauge the improvement of your typing abilities.

Typing.com
You will find quick and efficient typing drills that provide a measure of your speed and accuracy according to the time taken to complete them. Explore different levels of typing to improve your speed and coordination.

Keybr.com
Practice typing consonant and vowel combinations that appear in the English Language. Build your typing speed and track your progress through a stats generator.
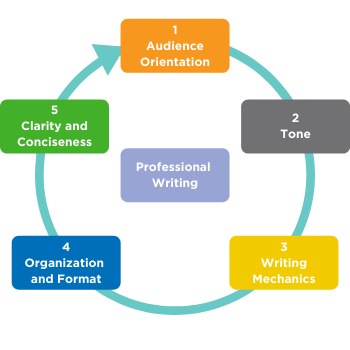
Consider your audience. What knowledge do they have about the subject of your communication? How will you tailor your response to their needs? What is your role and what are you trying to achieve?
The CPA Mindset is the first part of The CPA Way and demonstrates the attitudes and behaviours of a CPA. Communicating with a professional tone conveys respect, courtesy, sincerity, objectivity, integrity, and fairness in written documents such as emails, memos, and reports. Is the attitude you are expressing aligned with the CPA Mindset and appropriate to your given role and the audience?
Professional written communication adheres to proper writing mechanics. How well do you follow the rules of writing conventions? Example: punctuation, sentence structure, spelling, capitalization, and quotations?
Do you organize your information and arrange it to fit the type of communication you are using for reports, emails, memos, presentations etc.?
Conciseness and clarity provide the audience with the right amount of information needed for their understanding. How clear and precise is your communication, while remaining supported?
